


AEC API¶
By default, PettingZoo models games as Agent Environment Cycle (AEC) environments. This allows PettingZoo to represent any type of game multi-agent RL can consider.
For more information, see About AEC or PettingZoo: A Standard API for Multi-Agent Reinforcement Learning.
PettingZoo Wrappers can be used to convert between Parallel and AEC environments, with some restrictions (e.g., an AEC env must only update once at the end of each cycle).
Examples¶
PettingZoo Classic provides standard examples of AEC environments for turn-based games, many of which implement Illegal Action Masking.
We provide a tutorial for creating a simple Rock-Paper-Scissors AEC environment, showing how games with simultaneous actions can also be represented with AEC environments.
Usage¶
AEC environments can be interacted with as follows:
from pettingzoo.classic import rps_v2
env = rps_v2.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
action = env.action_space(agent).sample() # this is where you would insert your policy
env.step(action)
env.close()
Action Masking¶
AEC environments often include action masks, in order to mark valid/invalid actions for the agent.
To sample actions using action masking:
from pettingzoo.classic import chess_v6
env = chess_v6.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# invalid action masking is optional and environment-dependent
if "action_mask" in info:
mask = info["action_mask"]
elif isinstance(observation, dict) and "action_mask" in observation:
mask = observation["action_mask"]
else:
mask = None
action = env.action_space(agent).sample(mask) # this is where you would insert your policy
env.step(action)
env.close()
Note: action masking is optional, and can be implemented using either observation or info.
PettingZoo Classic environments store action masks in the
observationdict:mask = observation["action_mask"]
Shimmy’s OpenSpiel environments stores action masks in the
infodict:mask = info["action_mask"]
To implement action masking in a custom environment, see Custom Environment: Action Masking
For more information on action masking, see A Closer Look at Invalid Action Masking in Policy Gradient Algorithms (Huang, 2022)
About AEC¶
The Agent Environment Cycle (AEC) model was designed as a Gym-like API for MARL, supporting all possible use cases and types of environments. This includes environments with:
Large number of agents (see Magent2)
Variable number of agents (see Knights, Archers, Zombies)
Action and observation spaces of any type (e.g., Box, Discrete, MultiDiscrete, MultiBinary, Text)
Nested action and observation spaces (e.g., Dict, Tuple, Sequence, Graph)
Support for action masking (see Classic environments)
Action and observation spaces which can change over time, and differ per agent (see generated_agents and variable_env_test)
Changing turn order and evolving environment dynamics (e.g., games with multiple stages, reversing turns)
In an AEC environment, agents act sequentially, receiving updated observations and rewards before taking an action. The environment updates after each agent’s step, making it a natural way of representing sequential games such as Chess. The AEC model is flexible enough to handle any type of game that multi-agent RL can consider.
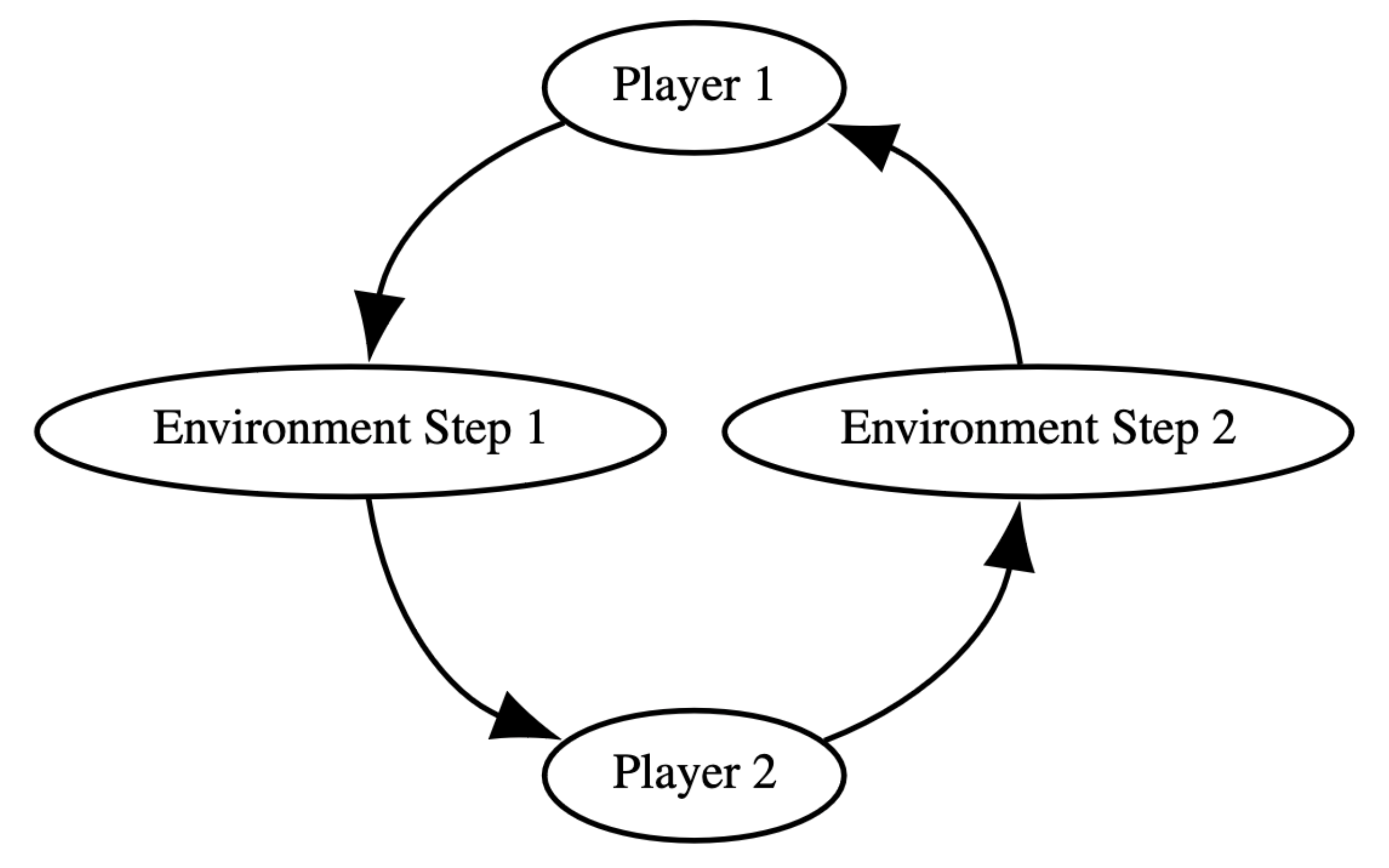
This is in contrast to the Partially Observable Stochastic Game (POSG) model, represented in our Parallel API, where agents act simultaneously and can only receive observations and rewards at the end of a cycle. This makes it difficult to represent sequential games, and results in race conditions–where agents choose to take actions which are mutually exclusive. This causes environment behavior to differ depending on internal resolution of agent order, resulting in hard-to-detect bugs if even a single race condition is not caught and handled by the environment (e.g., through tie-breaking).
The AEC model is similar to Extensive Form Games (EFGs) model, used in DeepMind’s OpenSpiel. EFGs represent sequential games as trees, explicitly representing every possible sequence of actions as a root to leaf path in the tree. A limitation of EFGs is that the formal definition is specific to game-theory, and only allows rewards at the end of a game, whereas in RL, learning often requires frequent rewards.
EFGs can be extended to represent stochastic games by adding a player representing the environment (e.g., chance nodes in OpenSpiel), which takes actions according to a given probability distribution. However, this requires users to manually sample and apply chance node actions whenever interacting with the environment, leaving room for user error and potential random seeding issues.
AEC environments, in contrast, handle environment dynamics internally after each agent step, resulting in a simpler mental model of the environment, and allowing for arbitrary and evolving environment dynamics (as opposed to static chance distribution). The AEC model also more closely resembles how computer games are implemented in code, and can be thought of similar to the game loop in game programming.
For more information about the AEC model and PettingZoo’s design philosophy, see PettingZoo: A Standard API for Multi-Agent Reinforcement Learning.
AECEnv¶
Attributes¶
- AECEnv.agents: list[AgentID]¶
A list of the names of all current agents, typically integers. These may be changed as an environment progresses (i.e. agents can be added or removed).
- Type:
List[AgentID]
- AECEnv.num_agents¶
The length of the agents list.
- AECEnv.possible_agents: list[AgentID]¶
A list of all possible_agents the environment could generate. Equivalent to the list of agents in the observation and action spaces. This cannot be changed through play or resetting.
- Type:
List[AgentID]
- AECEnv.max_num_agents¶
The length of the possible_agents list.
- AECEnv.agent_selection: AgentID¶
An attribute of the environment corresponding to the currently selected agent that an action can be taken for.
- Type:
AgentID
- AECEnv.terminations: dict[AgentID, bool]¶
- AECEnv.truncations: dict[AgentID, bool]¶
- AECEnv.rewards: dict[AgentID, float]¶
A dict of the rewards of every current agent at the time called, keyed by name. Rewards the instantaneous reward generated after the last step. Note that agents can be added or removed from this attribute. last() does not directly access this attribute, rather the returned reward is stored in an internal variable. The rewards structure looks like:
{0:[first agent reward], 1:[second agent reward] ... n-1:[nth agent reward]}
- Type:
Dict[AgentID, float]
- AECEnv.infos: dict[AgentID, dict[str, Any]]¶
A dict of info for each current agent, keyed by name. Each agent’s info is also a dict. Note that agents can be added or removed from this attribute. last() accesses this attribute. The returned dict looks like:
infos = {0:[first agent info], 1:[second agent info] ... n-1:[nth agent info]}
- Type:
Dict[AgentID, Dict[str, Any]]
- AECEnv.observation_spaces: dict[AgentID, Space]¶
A dict of the observation spaces of every agent, keyed by name. This cannot be changed through play or resetting.
- Type:
Dict[AgentID, gymnasium.spaces.Space]
- AECEnv.action_spaces: dict[AgentID, Space]¶
A dict of the action spaces of every agent, keyed by name. This cannot be changed through play or resetting.
- Type:
Dict[AgentID, gymnasium.spaces.Space]
Methods¶
- AECEnv.step(action: ActionType) None[source]¶
Accepts and executes the action of the current agent_selection in the environment.
Automatically switches control to the next agent.
- AECEnv.reset(seed: int | None = None, options: dict | None = None) None[source]¶
Resets the environment to a starting state.
- AECEnv.observe(agent: AgentID) ObsType | None[source]¶
Returns the observation an agent currently can make.
last() calls this function.
- AECEnv.render() None | ndarray | str | list[source]¶
Renders the environment as specified by self.render_mode.
Render mode can be human to display a window. Other render modes in the default environments are ‘rgb_array’ which returns a numpy array and is supported by all environments outside of classic, and ‘ansi’ which returns the strings printed (specific to classic environments).