


Pursuit¶
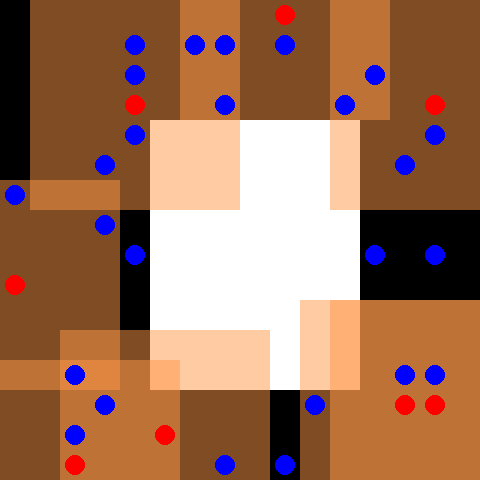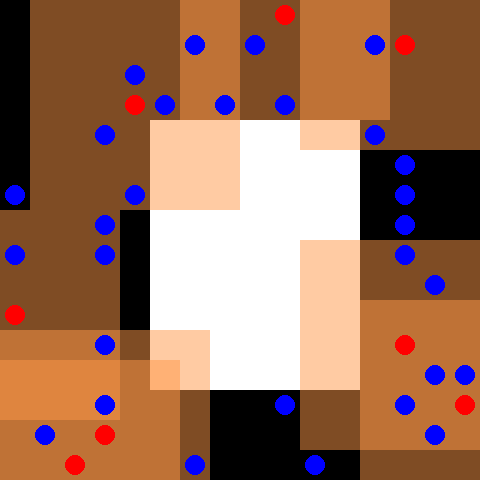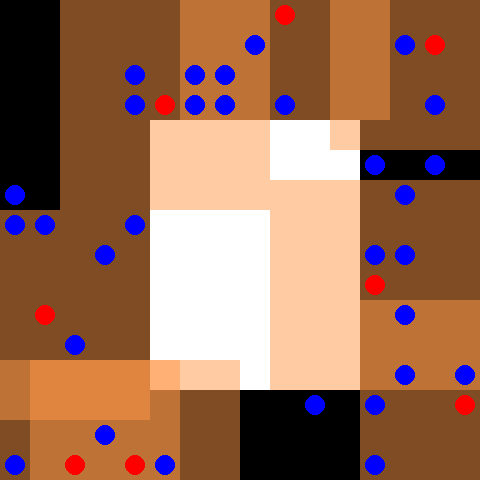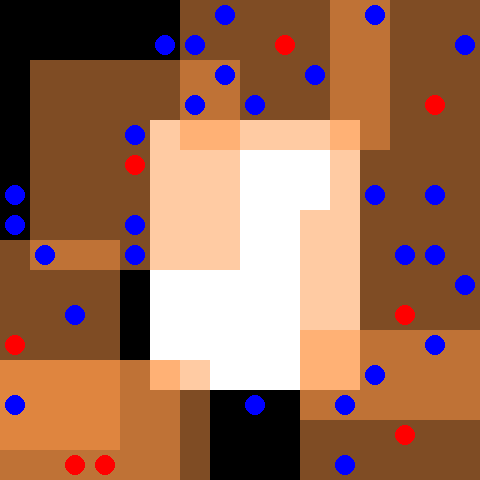
This environment is part of the SISL environments. Please read that page first for general information.
Import |
|
|---|---|
Actions |
Discrete |
Parallel API |
Yes |
Manual Control |
Yes |
Agents |
|
Agents |
8 (+/-) |
Action Shape |
(5) |
Action Values |
Discrete(5) |
Observation Shape |
(7, 7, 3) |
Observation Values |
[0, 30] |
By default 30 blue evader agents and 8 red pursuer agents are placed in a 16 x 16 grid with an obstacle, shown in white, in the center. The evaders move randomly, and the pursuers are controlled. Every time the pursuers fully surround an evader each of the surrounding agents receives a reward of 5 and the evader is removed from the environment. Pursuers also receive a reward of 0.01 every time they touch an evader. The pursuers have a discrete action space of up, down, left, right and stay. Each pursuer observes a 7 x 7 grid centered around itself, depicted by the orange boxes surrounding the red pursuer agents. The environment terminates when every evader has been caught, or when 500 cycles are completed. Note that this environment has already had the reward pruning optimization described in section 4.1 of the PettingZoo paper applied.
Observation shape takes the full form of (obs_range, obs_range, 3) where the first channel is 1s where there is a wall, the second channel indicates the number of allies in each coordinate and the third channel indicates the number of opponents in each coordinate.
Manual Control¶
Select different pursuers with ‘J’ and ‘K’. The selected pursuer can be moved with the arrow keys.
Arguments¶
pursuit_v4.env(max_cycles=500, x_size=16, y_size=16, shared_reward=True, n_evaders=30,
n_pursuers=8,obs_range=7, n_catch=2, freeze_evaders=False, tag_reward=0.01,
catch_reward=5.0, urgency_reward=-0.1, surround=True, constraint_window=1.0)
x_size, y_size: Size of environment world space
shared_reward: Whether the rewards should be distributed among all agents
n_evaders: Number of evaders
n_pursuers: Number of pursuers
obs_range: Size of the box around the agent that the agent observes.
n_catch: Number pursuers required around an evader to be considered caught
freeze_evaders: Toggles if evaders can move or not
tag_reward: Reward for ‘tagging’, or being single evader.
term_pursuit: Reward added when a pursuer or pursuers catch an evader
urgency_reward: Reward to agent added in each step
surround: Toggles whether evader is removed when surrounded, or when n_catch pursuers are on top of evader
constraint_window: Size of box (from center, in proportional units) which agents can randomly spawn into the environment world. Default is 1.0, which means they can spawn anywhere on the map. A value of 0 means all agents spawn in the center.
max_cycles: After max_cycles steps all agents will return done
Version History¶
v4: Change the reward sharing, fix a collection bug, add agent counts to the rendering (1.14.0)
v3: Observation space bug fixed (1.5.0)
v2: Misc bug fixes (1.4.0)
v1: Various fixes and environment argument changes (1.3.1)
v0: Initial versions release (1.0.0)
Usage¶
AEC¶
from pettingzoo.sisl import pursuit_v4
env = pursuit_v4.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# this is where you would insert your policy
action = env.action_space(agent).sample()
env.step(action)
env.close()
Parallel¶
from pettingzoo.sisl import pursuit_v4
env = pursuit_v4.parallel_env(render_mode="human")
observations, infos = env.reset()
while env.agents:
# this is where you would insert your policy
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
observations, rewards, terminations, truncations, infos = env.step(actions)
env.close()
API¶
- class pettingzoo.sisl.pursuit.pursuit.raw_env(*args, **kwargs)[source]¶
- action_space(agent: str)[source]¶
Takes in agent and returns the action space for that agent.
MUST return the same value for the same agent name
Default implementation is to return the action_spaces dict
- close()[source]¶
Closes any resources that should be released.
Closes the rendering window, subprocesses, network connections, or any other resources that should be released.
- observation_space(agent: str)[source]¶
Takes in agent and returns the observation space for that agent.
MUST return the same value for the same agent name
Default implementation is to return the observation_spaces dict
- observe(agent)[source]¶
Returns the observation an agent currently can make.
last() calls this function.
- render()[source]¶
Renders the environment as specified by self.render_mode.
Render mode can be human to display a window. Other render modes in the default environments are ‘rgb_array’ which returns a numpy array and is supported by all environments outside of classic, and ‘ansi’ which returns the strings printed (specific to classic environments).