


Waterworld¶
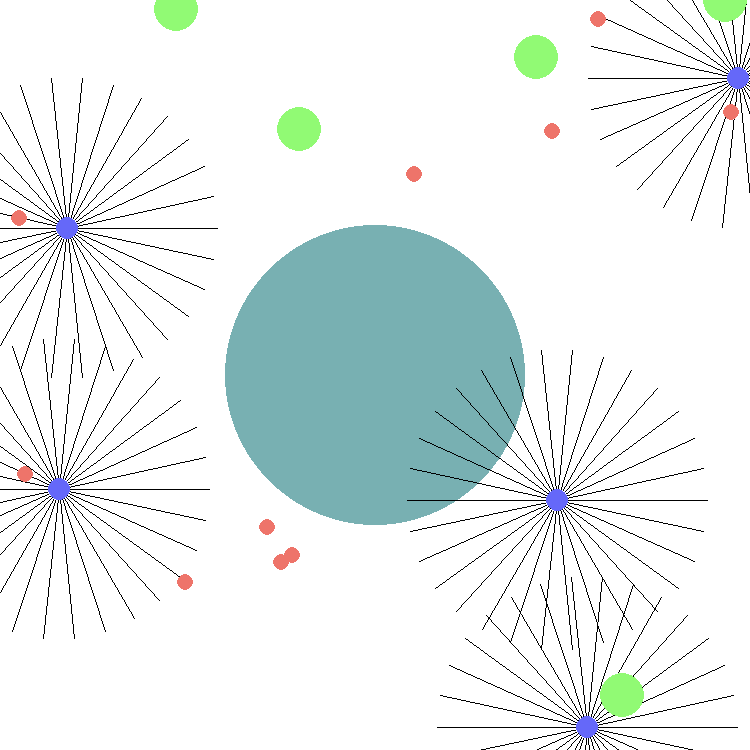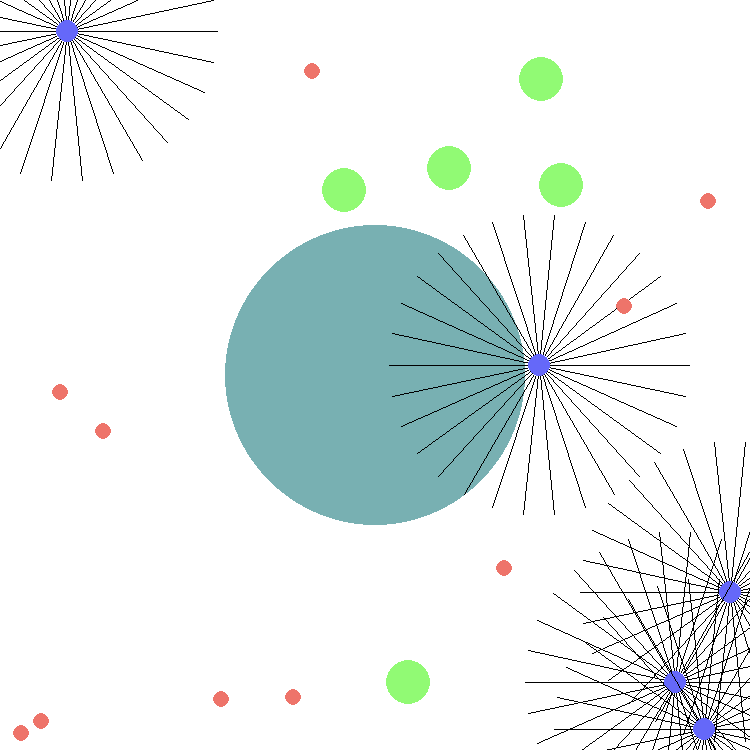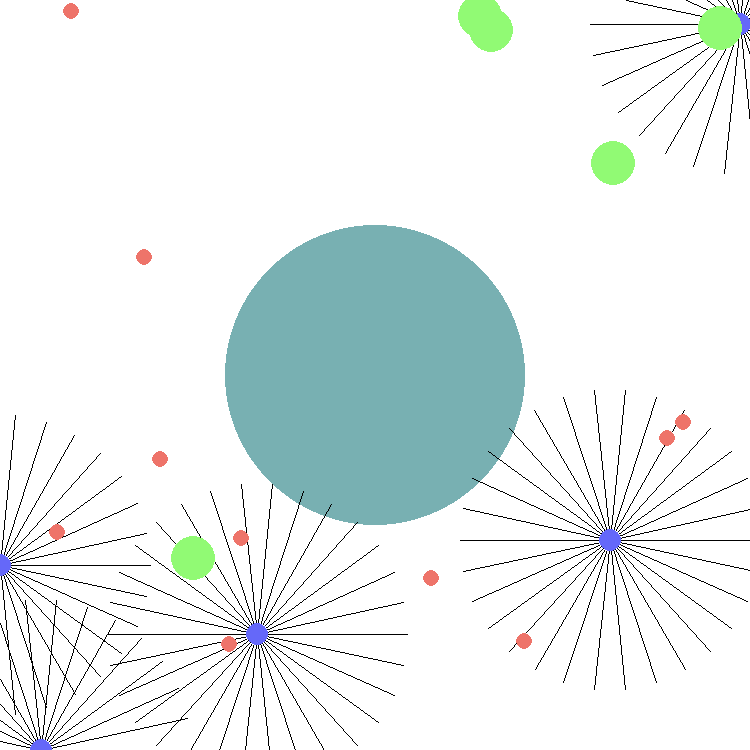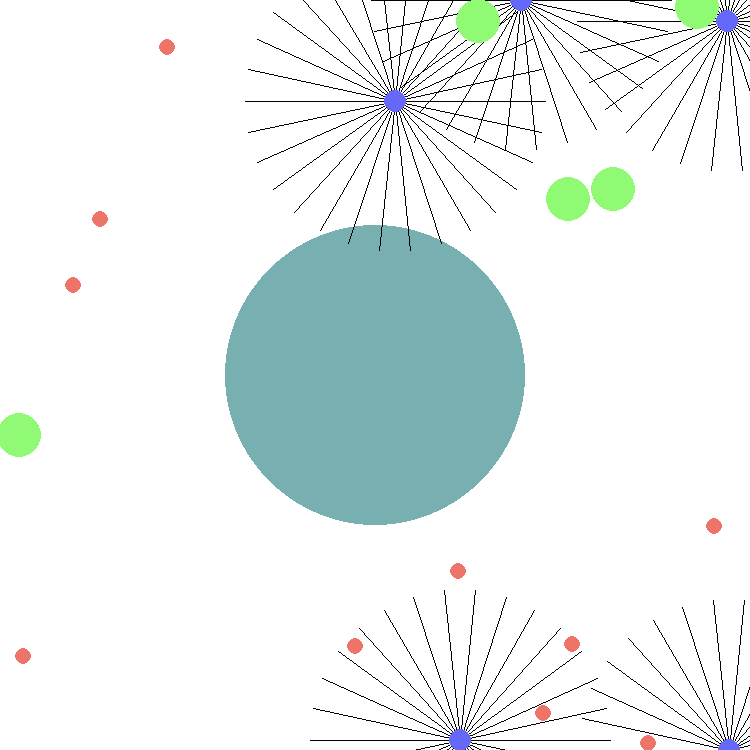
This environment is part of the SISL environments. Please read that page first for general information.
Import |
|
|---|---|
Actions |
Continuous |
Parallel API |
Yes |
Manual Control |
No |
Agents |
|
Agents |
5 |
Action Shape |
(2,) |
Action Values |
[-0.01, 0.01] |
Observation Shape |
(242,) |
Observation Values |
[-√2, 2*√2] |
Waterworld is a simulation of archea navigating and trying to survive in their environment. These archea, called pursuers attempt to consume food while avoiding poison. The agents in waterworld are the pursuers, while food and poison belong to the environment. Poison has a radius which is 0.75 times the size of the pursuer radius, while food has a radius 2 times the size of the pursuer radius. Depending on the input parameters, multiple pursuers may need to work together to consume food, creating a dynamic that is both cooperative and competitive. Similarly, rewards can be distributed globally to all pursuers, or applied locally to specific pursuers. The environment is a continuous 2D space, and each pursuer has a position with x and y values each in the range [0,1]. Agents can not move beyond barriers at the minimum and maximum x and y values. Agents act by choosing a thrust vector to add to their current velocity. Each pursuer has a number of evenly spaced sensors which can read the speed and direction of objects near the pursuer. This information is reported in the observation space, and can be used to navigate the environment.
Observation Space¶
The observation shape of each agent is a vector of length > 4 that is dependent on the environment’s input arguments. The full size of the vector is the number of features per sensor multiplied by the number of sensors, plus two elements indicating whether the pursuer collided with food or with
poison respectively. The number of features per sensor is 8 by default with speed_features enabled, or 5 if speed_features is turned off. Therefore with speed_features enabled, the observation shape takes the full form of (8 × n_sensors) + 2. Elements of the observation vector take on
values in the range [-1, 1].
For example, by default there are 5 agents (purple), 5 food targets (green) and 10 poison targets (red). Each agent has 30 range-limited sensors, depicted by the black lines, to detect neighboring entities (food and poison targets) resulting in 242 element vector of computed values about the environment for the observation space. These values represent the distances and speeds sensed by each sensor on the archea. Sensors that do not sense any objects within their range report 0 for speed and 1 for distance.
This has been fixed from the reference environments to keep items floating off screen and being lost forever.
This table enumerates the observation space with speed_features = True:
Index: [start, end) |
Description |
Values |
|---|---|---|
0 to n_sensors |
Obstacle distance for each sensor |
[0, 1] |
n_sensors to (2 * n_sensors) |
Barrier distance for each sensor |
[0, 1] |
(2 * n_sensors) to (3 * n_sensors) |
Food distance for each sensor |
[0, 1] |
(3 * n_sensors) to (4 * n_sensors) |
Food speed for each sensor |
[-2√2, 2√2] |
(4 * n_sensors) to (5 * n_sensors) |
Poison distance for each sensor |
[0, 1] |
(5 * n_sensors) to (6 * n_sensors) |
Poison speed for each sensor |
[-2√2, 2√2] |
(6 * n_sensors) to (7 * n_sensors) |
Pursuer distance for each sensor |
[0, 1] |
(7 * n_sensors) to (8 * n_sensors) |
Pursuer speed for each sensor |
[-2√2, 2√2] |
8 * n_sensors |
Indicates whether agent collided with food |
{0, 1} |
(8 * n_sensors) + 1 |
Indicates whether agent collided with poison |
{0, 1} |
This table enumerates the observation space with speed_features = False:
Index: [start, end) |
Description |
Values |
|---|---|---|
0 - n_sensors |
Obstacle distance for each sensor |
[0, 1] |
n_sensors - (2 * n_sensors) |
Barrier distance for each sensor |
[0, 1] |
(2 * n_sensors) - (3 * n_sensors) |
Food distance for each sensor |
[0, 1] |
(3 * n_sensors) - (4 * n_sensors) |
Poison distance for each sensor |
[0, 1] |
(4 * n_sensors) - (5 * n_sensors) |
Pursuer distance for each sensor |
[0, 1] |
(5 * n_sensors) |
Indicates whether agent collided with food |
{0, 1} |
(5 * n_sensors) + 1 |
Indicates whether agent collided with poison |
{0, 1} |
Action Space¶
The agents have a continuous action space represented as a 2 element vector, which corresponds to horizontal and vertical thrust. The range of values depends on pursuer_max_accel. Action values must be in the range [-pursuer_max_accel, pursuer_max_accel]. If the magnitude of this action
vector exceeds pursuer_max_accel, it will be scaled down to pursuer_max_accel. This velocity vector is added to the archea’s current velocity.
Agent action space: [horizontal_thrust, vertical_thrust]
Rewards¶
When multiple agents (depending on n_coop) capture food together each agent receives a reward of food_reward (the food is not destroyed). They receive a shaping reward of encounter_reward for touching food, a reward of poison_reward for touching poison, and a thrust_penalty x ||action||
reward for every action, where ||action|| is the euclidean norm of the action velocity. All of these rewards are also distributed based on local_ratio, where the rewards scaled by local_ratio (local rewards) are applied to the agents whose actions produced the rewards, and the rewards
averaged over the number of agents (global rewards) are scaled by (1 - local_ratio) and applied to every agent. The environment runs for 500 frames by default.
Arguments¶
waterworld_v4.env(n_pursuers=5, n_evaders=5, n_poisons=10, n_coop=2, n_sensors=20,
sensor_range=0.2,radius=0.015, obstacle_radius=0.2, n_obstacles=1,
obstacle_coord=[(0.5, 0.5)], pursuer_max_accel=0.01, evader_speed=0.01,
poison_speed=0.01, poison_reward=-1.0, food_reward=10.0, encounter_reward=0.01,
thrust_penalty=-0.5, local_ratio=1.0, speed_features=True, max_cycles=500)
n_pursuers: number of pursuing archea (agents)
n_evaders: number of food objects
n_poisons: number of poison objects
n_coop: number of pursuing archea (agents) that must be touching food at the same time to consume it
n_sensors: number of sensors on all pursuing archea (agents)
sensor_range: length of sensor dendrite on all pursuing archea (agents)
radius: archea base radius. Pursuer: radius, food: 2 x radius, poison: 3/4 x radius
obstacle_radius: radius of obstacle object
obstacle_coord: coordinate of obstacle object. Can be set to None to use a random location
pursuer_max_accel: pursuer archea maximum acceleration (maximum action size)
pursuer_speed: pursuer (agent) maximum speed
evader_speed: food speed
poison_speed: poison speed
poison_reward: reward for pursuer consuming a poison object (typically negative)
food_reward: reward for pursuers consuming a food object
encounter_reward: reward for a pursuer colliding with a food object
thrust_penalty: scaling factor for the negative reward used to penalize large actions
local_ratio: Proportion of reward allocated locally vs distributed globally among all agents
speed_features: toggles whether pursuing archea (agent) sensors detect speed of other objects and archea
max_cycles: After max_cycles steps all agents will return done
v4: Major refactor (1.22.0)
v3: Refactor and major bug fixes (1.5.0)
v2: Misc bug fixes (1.4.0)
v1: Various fixes and environment argument changes (1.3.1)
v0: Initial versions release (1.0.0)
Usage¶
AEC¶
from pettingzoo.sisl import waterworld_v4
env = waterworld_v4.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# this is where you would insert your policy
action = env.action_space(agent).sample()
env.step(action)
env.close()
Parallel¶
from pettingzoo.sisl import waterworld_v4
env = waterworld_v4.parallel_env(render_mode="human")
observations, infos = env.reset()
while env.agents:
# this is where you would insert your policy
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
observations, rewards, terminations, truncations, infos = env.step(actions)
env.close()
API¶
- class pettingzoo.sisl.waterworld.waterworld.raw_env(*args, **kwargs)[source]¶
- action_space(agent)[source]¶
Takes in agent and returns the action space for that agent.
MUST return the same value for the same agent name
Default implementation is to return the action_spaces dict
- close()[source]¶
Closes any resources that should be released.
Closes the rendering window, subprocesses, network connections, or any other resources that should be released.
- observation_space(agent)[source]¶
Takes in agent and returns the observation space for that agent.
MUST return the same value for the same agent name
Default implementation is to return the observation_spaces dict
- observe(agent)[source]¶
Returns the observation an agent currently can make.
last() calls this function.
- render()[source]¶
Renders the environment as specified by self.render_mode.
Render mode can be human to display a window. Other render modes in the default environments are ‘rgb_array’ which returns a numpy array and is supported by all environments outside of classic, and ‘ansi’ which returns the strings printed (specific to classic environments).