


Simple Tag#
This environment is part of the MPE environments. Please read that page first for general information.
Import |
|
|---|---|
Actions |
Discrete/Continuous |
Parallel API |
Yes |
Manual Control |
No |
Agents |
|
Agents |
4 |
Action Shape |
(5) |
Action Values |
Discrete(5)/Box(0.0, 1.0, (50)) |
Observation Shape |
(14),(16) |
Observation Values |
(-inf,inf) |
State Shape |
(62,) |
State Values |
(-inf,inf) |
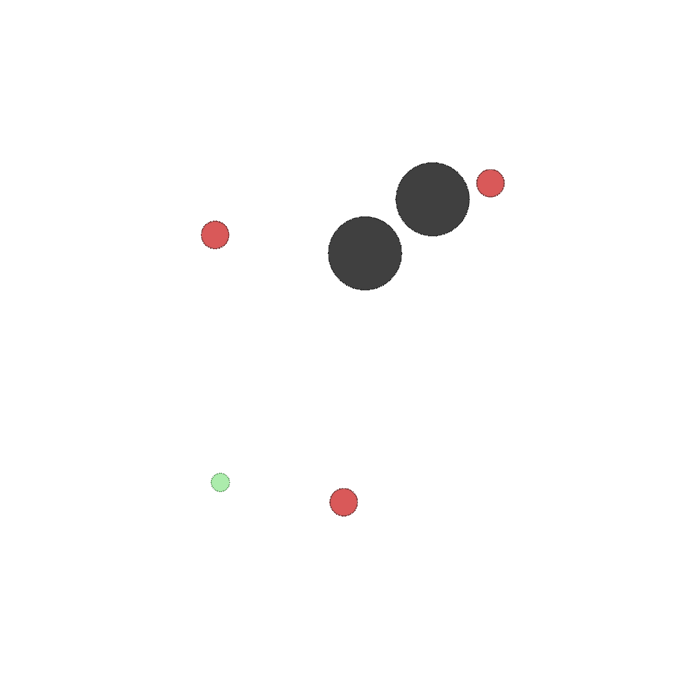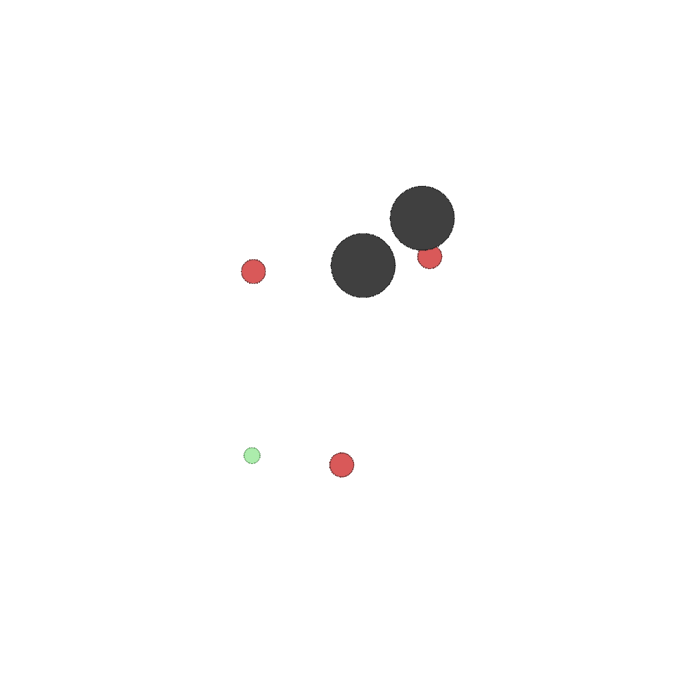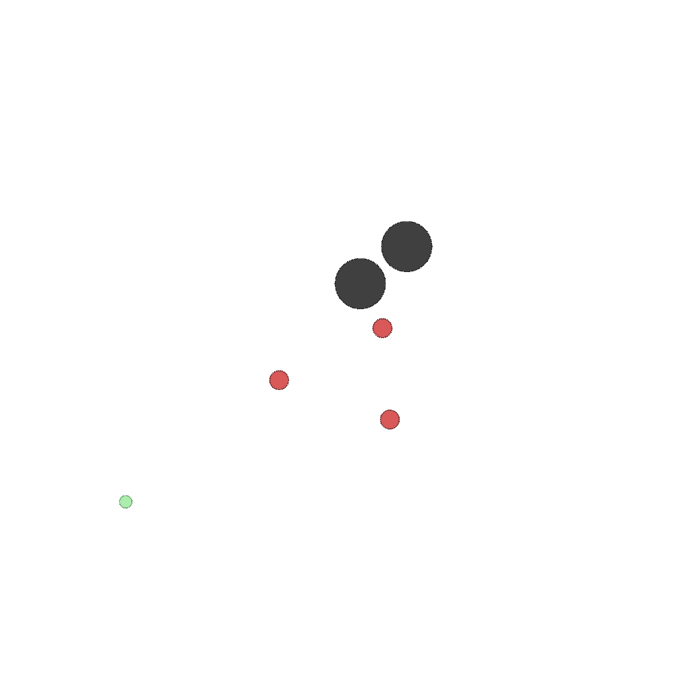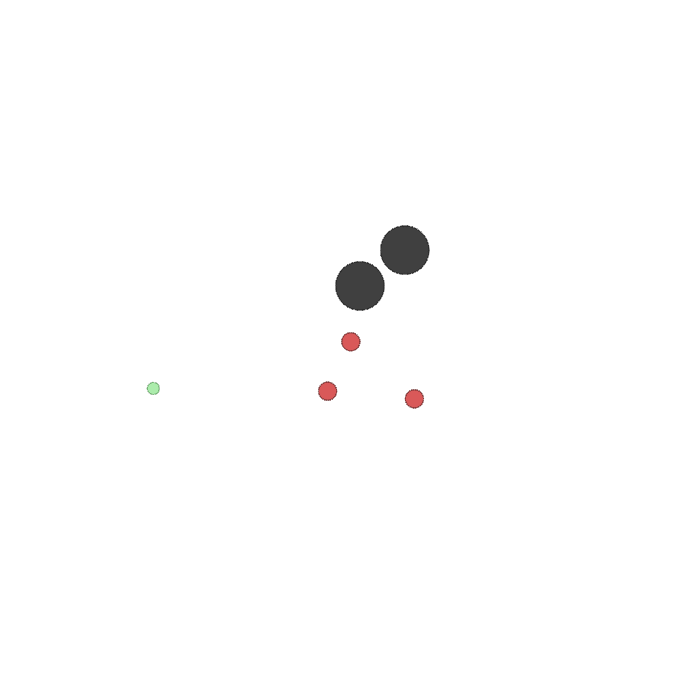
This is a predator-prey environment. Good agents (green) are faster and receive a negative reward for being hit by adversaries (red) (-10 for each collision). Adversaries are slower and are rewarded for hitting good agents (+10 for each collision). Obstacles (large black circles) block the way. By default, there is 1 good agent, 3 adversaries and 2 obstacles.
So that good agents don’t run to infinity, they are also penalized for exiting the area by the following function:
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10)
Agent and adversary observations: [self_vel, self_pos, landmark_rel_positions, other_agent_rel_positions, other_agent_velocities]
Agent and adversary action space: [no_action, move_left, move_right, move_down, move_up]
Arguments#
simple_tag_v3.env(num_good=1, num_adversaries=3, num_obstacles=2, max_cycles=25, continuous_actions=False)
num_good: number of good agents
num_adversaries: number of adversaries
num_obstacles: number of obstacles
max_cycles: number of frames (a step for each agent) until game terminates
continuous_actions: Whether agent action spaces are discrete(default) or continuous
API#
- class pettingzoo.mpe.simple_tag.simple_tag.raw_env(num_good=1, num_adversaries=3, num_obstacles=2, max_cycles=25, continuous_actions=False, render_mode=None)[source]#
Uses the
argsandkwargsfrom the object’s constructor for pickling.- action_spaces: dict[AgentID, gymnasium.spaces.Space]#
- agent_selection: AgentID#
- agents: list[AgentID]#
- infos: dict[AgentID, dict[str, Any]]#
- observation_spaces: dict[AgentID, gymnasium.spaces.Space]#
- possible_agents: list[AgentID]#
- rewards: dict[AgentID, float]#
- terminations: dict[AgentID, bool]#
- truncations: dict[AgentID, bool]#